Big Data vs. User Experience




Right there is one of the great buzzwords these days: “Big Data”.
You’ve probably heard it this week, maybe even today, and you may also have noticed the positive connotations that cling to the term – the glowing, almost awestruck tone, and the shared assumption that this concept holds all the answers.
Specifically, all the answers to our questions about our customers and/or users.
It’s understood (if not explicit) that with the help of technology we can now finally, informally gather so much data on people that by digging into it, we may find any pattern they might hold. Customers will be an open book to us.

Now, there’s nothing we cannot know about them.
Let’s have a look at it – and let’s start with the assumption that the more data you have, the more informed you are. This assumption is widely held, but it actually isn’t true. The connection between the amount of data and the quality of the result isn’t as strong as you might think.
We know if from our own experience: Sometimes our ability to arrive at a conclusion suffers from too many options, and/or too much information about each option. Studies confirm this – under controlled conditions it’s also found that both ability to decide and quality of the decision deteriorates with growing data quantities.
There’s an expectation that computers will be better at this than we are because they aren’t hampered by human limitations, and their behavior can be programmed and defined exactly as we want them.
There’s a level of truth in this; at present our data fields are so big, our current computers can’t handle them within practical time limits, but as computers grow faster these limits will be pushed. However, there’s also a tendency for things to become “statistical” when we get to these scales – that is, errors and flaws emerge, and we start to see behaviors which, for lack of a better term, could be classified as “subjective, or even “irrational”.
This may be easier to understand if we look at just how much data we’re dealing with. Consider, for example, that Microsoft alone has more than a million individual servers, and Google stores so much data that if it was transferred to punch cards, it could cover an area the size of Great Britain to a depth of four kilometers, or more than two-and-a-half miles. Yet even figures like these pale next to the speeds that are in play – Google handles more than a thousand times the information of the entire US Congressional Library every day, with similar numbers for Facebook, Amazon and other services. These are the heavy hitters, of course, but even more “normal” datasets easily contain hundreds of terabytes of data.
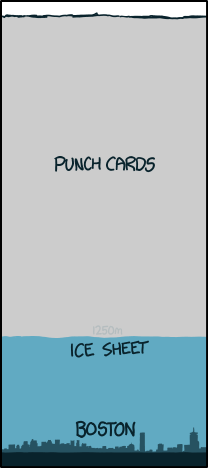
image from XKCD, of course
We also know that there’s a lower limit to how much you can simplify a complex set of conditions (often called “a system”) without compromising its original significance. Simply put, some systems are so complex, any reasonably faithful representation or analysis of them will have to be pretty complex itself. The point is, a data set which covers the behavior of a very large number of people, registered at many individual data points (such as clicks or likes, not to mention time markers, GPS etc.) will necessarily be enormously complex, and it’s unlikely that we can collapse it into some simple, accessible parameters and still have a meaningful picture of the system as a whole. This principle is independent of speed and computing power, and we have to take it into consideration regardless of the advances in technology.
All this is not to say that big data, or the analysis thereof, is useless, which would be untrue (and kind of stupid). As mentioned things get statistical at these levels but it’s not like we don’t know a lot about how to do statistics – as long as we remember that any statistical interpretation is just that; a interpretation. No matter how much data we get, or how fast our computers become, we may never know “everything”, because even if we did, we couldn’t condense it into a useful form on any realistic time scale.
So perhaps those annoying, human characteristics of our own minds that we hope to eliminate through the use of computers aren’s so much attributes of our brains, but just the way things are when dealing with very large quantities of data very fast and turn them into something that’s useful for a certain context – remember, the brain is something of a computer in its own right (though it isn’t actually a computer).
Just like we need experts in numbers and statistics to help crunch these vast data sets, we also need experts in human behavior – that is, people like me – to achieve a productive understanding of users and/or customers.
My final observation is somewhat more prosaic (phew!) – namely this: To be able to see the behavior of our audience in these Big Data sets, the behavior has to have taken place, which means that Big Data is something that comes in after the fact.
We use these post-hoc data sets in user/customer experience and behavior, of course, but what we’re particularly good at, and data sets are not, is addressing behavior in advance, before a product or service is rolled out – one of our core services is helping you predict, and thus avoid, costly mistakes.
How we do this will be the subject of later articles. Stay tuned.