Kunstig intelligens, aktøren og valget




Der tales en masse om kunstig intelligens – eller AI, “artificial intelligence” – for tiden, det har du nok bemærket. Så sent som i denne uge sluttede Steve Wozniak, en af grundlæggerne af Apple, sig til koret af stemmer, der advarer mod de potentielle farer ved AI.
Samtidig er der virksomheder verden over, og over hele spektret fra Google, Facebook og Microsoft til lavbudget-startups, der lover en gylden fremtid for både livet og teknologien takket være intelligente maskiner – budskabet er, at vi snart vil slippe helt for at træffe kedelige valg, for computere vil blive så smarte at de vil lære dig at kende som en ven, og træffe dem for dig.
Og nu føjer jeg så min egen nasale røst til også – men som altid er min vinkel en lille smule anderledes.

Det er ikke lige mit ekspertise-område, men jeg er faktisk ikke sikker på at vi vil se stærk AI i maskiner foreløbig – men sagen er at det ikke betyder så meget i forhold til disse emner. Vi er udmærket i stand til at skabe problemer, selv farlige problemer, med de computere vi har nu, og vi ser også allerede nu store spring i forhold til valg og beslutninger.
Grunden til at det ikke har så stor betydning er, at det ikke så meget er maskinernes intelligens, der er det store spørgsmål – det er hvilken aktør-rolle, vi giver dem. Nu er jeg jo sådan en rådgiver, der hjælper virksomheder med at eksistere og trives i den moderne verden, så jeg har selvfølgelig ikke tænkt mig at skræmme alle væk fra dette, som alligevel ligger lige foran os. I stedet vil jeg tale lidt om, hvilke overvejelser vi bør gøre os, hvis vi vil have mest muligt ud af det.
Når vi taler om aktør-rollen, kan vi betjene os af en overlappende skala i stil med denne:

Vi skal finde ud af, hvor på den skala vi befinder os – eller ønsker at befinde os. “Vi” betyder her enhver afsender af et produkt eller en ydelse, men det betyder også, og i væsentlig grad, brugerne. Det er værd at understrege, at der ikke er noget grundlæggende i vejen med nogen af skalaens ender. Visse ting har det bedst med at være menneske-valg, andre ting kan en maskin-aktør sagtens håndtere, og rigtig mange ting skal helst have en passende blanding af menneske- og maskin-aktør ind over.
Men det er vigtigt, at vi vælger niveauet bevidst.
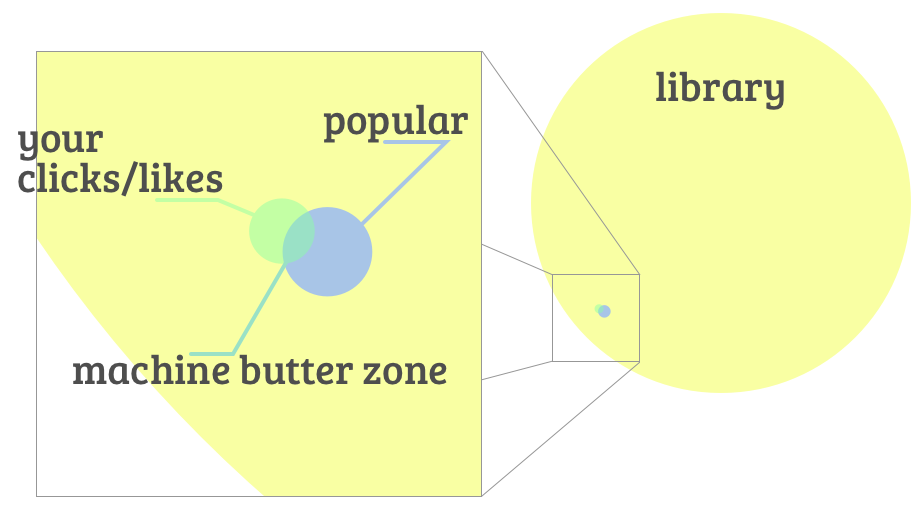
Lad os tage et tidssvarende eksempel: Dit nyheds-feed. Du ved, hvad det nu består i – et udvalg af avis-hjemmesider, en app, Facebook eller noget andet. Vi ved allesammen godt at der er al for megen information derude, men der er forskellige måder at håndtere dette på. På Facebook, for eksempel, er dit indhold allerede filtreret – filtrene antager, at du gerne vil have mere af det indhold, du reagerer på ved at klikke og like, og så præsenteres du for “mere af det samme” (efter en opskrift vi ikke kender). Effekten af denne form for filtrering er en slags omvendt tragt; du bliver vist indhold, der regnes for “populært” hos dig, og så interagerer du med en del af det, og så vises du mere af denne del osv.
Vi ser den samme omvendt-tragt-effekt overalt hvor der er en popularitets-algoritme af en eller anden art. Tjek for eksempel din musik-streaming-service – dér er der en meget lille del af det samlede bibliotek, der får massiv eksponering, med resten fordelt ned gennem den omvendte tragt, der her er meget stejl; langt det meste af biblioteket får meget lidt eksponering (på Spotify er der f.eks. omkring 4 millioner sange, der aldrig er blevet spillet, omkring 20% af biblioteket). Brugerne præsenteres for et “populært nu”-udvalg, som bliver smallere når man interagerer med det.
I den anden ende er der feeds som Twitter – dér finder ingen algoritmisk filtrering sted, men man kan kuratere sit indhold gennem sit valg af kilder. Derefter er det op til én selv at klikke eller lade være. De fleste nyheds-services – samlende eller individuelle – er heller ikke algoritmisk sorterede. I disse tilfælde er valget dit, og du skal træffe det igen og igen, hver gang du besøger feed’et.
Midt imellem, og med kurator-værktøjerne “front and center”, findes services i stil med Feedly, hvor man kan lave samlinger af kilder, gemme historier til senere m.m. En endnu mere kraftfuld kurator-værktøjskasse finder man på Cronycle, en start-up rettet mod folk, der navigerer disse feeds professionelt, og i teams – f.eks. i forbindelse med journalistisk arbejde, til research, for at samle inspiration og viden, og så videre.
Alt dette repræsenterer forskellige indgange til aktør-rollen, og computernes intelligens betyder ikke så meget. Det centrale spørgsmål, også selvom den er super-intelligent, er stadig: I hvor høj grad er du selv aktøren, og i hvor høj grad er service’en? Vi ved vi ikke kan se, læse eller høre alting, at noget bliver sorteret fra – vi skal bare tage stilling til hvordan denne sortering foregår, og hvem der står for den. Som jeg tidligere sagde er der ikke noget galt med nogen af alternativerne; det drejer sig om at vælge. Hvad vi skal gøre – på en helt udramatisk, konstruktiv og endda utilitarisk måde – er at finde ud af, hvordan, hvornår og hvorfor vi vil have maskiner, smarte eller ej, til at hjælpe os med at træffe bedre valg.
Om vi så laver og sælger dem, eller blot er brugere af dem.
hjerne-illustration via Wikimedia Commons – grafik Jesper W. of CPH